Generating Customized Exam Papers and Solutions using Python

Table of Contents
Context
Producing multiple versions of an exam is crucial to promote fairness and deter cheating. While specialized software can help in this effort, many users encounter challenges. Some of these include high costs and limited customization features. For instance, the “Auto Multiple Choice” (AMC) software is great for its auto-grading and analysis capabilities. However, it’s primarily tailored for Linux. While it can technically run on Windows, doing so requires navigating the intricacies of virtual machines—a task not all are comfortable with.
As I began my journey learning Python I decided to develop a script that can automate the exam creation process. This includes producing multiple exam versions, randomizing questions, and shuffling answer choices. More than just a learning experience, this tool offers a universal solution for those facing similar challenges.
Of course, starting this project as a Python newbie, I found invaluable assistance from ChatGPT 😄
Script Features
The proposed script is designed with the objective of simplifying the process of creating multiple versions of a test, thereby minimizing the likelihood of cheating while also making the procedure accessible on various operating systems. Below are the features of the script outlined:
-
Preparation of Input Files: The user is only required to prepare two Excel files as input; one containing open-ended questions and the other with multiple-choice questions. This straightforward preparation step minimizes the setup time while keeping the process organized.
-
Selection of Question Count: The user can decide the number of questions of each type (open-ended and multiple-choice) they want to include in the test. This feature allows for a tailored examination that fits the specific needs and duration constraints of the testing scenario.
-
Specification of Test Versions: The user can specify the number of different versions of the test they wish to generate. This feature is vital for maintaining a fair testing environment, especially in larger settings where the propensity for cheating might be higher.
-
Generation of Test and Solution Files: The script will generate the test papers in both PDF and LaTeX formats using the {exam} class. This dual-format output caters to different user preferences and further extends the script’s usability.
-
Solution Files: Alongside each test paper, a corresponding PDF file containing the solutions for each question will be generated. This automated solution generation feature simplifies the grading process and ensures that the solutions are accurately matched to the respective test versions.
-
Consistency and Accuracy: By utilizing the {exam} class, the script maintains a consistent formatting style across different test versions and ensures accurate representation of questions and answer choices.
Maintaining fairness in assessment is crucial to ensure a just and impartial testing environment. Here’s why, despite the generation of different test versions, each version will have the same set of questions, even if in a different random order. Having the same set of questions in each test version ensures that every student is assessed based on the same criteria, promoting equity. This is fundamental as differing question sets could lead to variations in difficulty levels, which in turn, could unfairly advantage or disadvantage certain students. This is definitely my choice, perhaps questionable, but for the time being I preferred to construct the script in this way.
Understanding Input File Structure
Before diving into the script analysis and its functionality, it’s essential to understand the structure that the two input files should have, one for open-ended questions and another for multiple-choice questions. These input files serve as the starting point upon which the script will operate to generate the desired test papers.
For the multiple-choice questions, the Excel file should follow a systematic structure to ensure that all necessary details are captured for each question. Below is an example of how the data should be organized within the Excel file:
| Question | Option A | Option B | Option C | Option D | Correct Answer | Image Path |
|---|---|---|---|---|---|---|
| Which planet is third from the sun? | Venus | Earth | Mars | Jupiter | B | |
| What is the capital of France? | Rome | Paris | London | Berlin | B | path/to/image.jpg |
| What is the largest mammal in the world? | Elephant | Whale | Hippopotamus | Rhinoceros | B | |
| Who wrote the play Romeo and Juliet? | Charles Dickens | William Shakespeare | Jane Austen | Mark Twain | B | |
| What is the square root of 64? | 6 | 7 | 8 | 9 | C | |
| In which year did the Titanic sink? | 1905 | 1912 | 1915 | 1920 | B | |
| What is the chemical symbol for water? | H2O | CO2 | O2 | N2 | A |
And similar for open-ended questions the structure of the input file must be:
| Question | Image Path |
|---|---|
| Describe your experience learning a new language. | |
| What factors contribute to a successful project? | |
| Explain a challenging problem you encountered and how you solved it. |
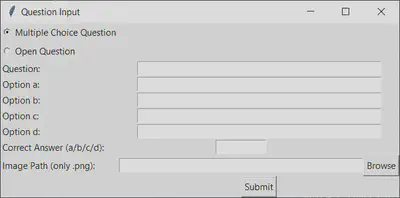
I am also working on a GUI that allows for easier insertion of questions into the two input sheets. This is likely to be part of a future development of the project. Below is an image showcasing the current state of the GUI. The idea is to enhance the graphical interface further, enabling the creation of exam copies directly from this platform. Now, it only facilitates the insertion of questions into the two input sheets.
Python Code
Necessary libraries are imported.While some libraries such as os and random are part of Python’s standard library, others need to be installed separately. In this article I’ll analyze only non standard libs.
Packages
fpdf is a library that allows for PDF document generation. With fpdf, you can create PDFs, add pages, set fonts, insert text, and even add images to your document. It’s a straightforward library that provides a lot of flexibility in PDF creation. PIL is a library for opening, manipulating, and saving many different image file formats. It’s now maintained under the name Pillow, which is a fork of the original PIL. It’s indispensable for tasks that require image processing such as cropping, resizing, and format conversion. jinja2 is a fast and extensible templating engine. It’s particularly useful when you need to generate documents dynamically. In this context, it’s being used for rendering .TeX templates, which can then be compiled into PDFs, providing a way to create beautifully formatted exams programmatically.
from fpdf import FPDF
import pandas as pd
import random
import os
from PIL import Image
from jinja2 import Environment, FileSystemLoader
PDF Class Definition
A new class named PDF is being created which inherits from the FPDF class from the fpdf library. By inheriting from FPDF, the PDF class will have all the functionality of the FPDF class, and is being extended to include additional behavior. The header and footer methods are special methods within the FPDF class that are automatically called whenever a new page is added or a page is finished rendering respectively. In this PDF class, these methods are being overridden to specify custom behavior for the header and footer of each page in the PDF document.
Within the header method of the PDF class, the set_font method is being called with parameters “Times”, “B”, and 12, to set the font of the header to Times, bold, with a size of 12, this will be the title of our exam. Similarly, within the footer method, the set_font method is being called with parameters “Times”, “I”, and 8, to set the font of the footer to Times, italic, with a size of 8. This way, whenever a new page is added to the PDF document, the header will have a bold font, and the footer will have an italic font, both in the Times font family but with different sizes.
class PDF(FPDF):
def header(self):
self.set_font("Times", "B", 12)
def footer(self):
self.set_font("Times", "I", 8)
Questions shuffle
The shuffle_mcq_choices function is central for randomizing the answer choices of MCQs. It takes a DataFrame row representing a question as input. Initially, it specifies a list of answer choices and retrieves the correct answer from the row. It then shuffles the choices using the random.sample function. Following that, it constructs a new list of shuffled options based on the shuffled choices. It also determines the new position of the correct answer post-shuffling. The function returns the shuffled options along with the position of the correct answer, which is essential for generating the answer key.
def shuffle_mcq_choices(row):
choices = ["a", "b", "c", "d"] # The original order of answer choices
correct = row['Correct Answer'] # The correct answer, which is "c" in this case
shuffled_choices = random.sample(choices, len(choices)) # Randomly shuffles the order of choices, e.g., ["b", "d", "a", "c"]
shuffled_options = [row[f"Option {choice}"] for choice in shuffled_choices] # Maps the shuffled choices back to the actual answer text, e.g., ["Madrid", "Rome", "Berlin", "Paris"]
correct_position = shuffled_choices.index(correct) # Finds the new position of the correct answer, which is 3 in this case (0-indexed)
return shuffled_options, correct_position # Returns the shuffled options and the position of the correct answer
The get_image_height function aids in handling images. Given an image path and a desired width, it calculates the corresponding height while maintaining the image’s original aspect ratio. This is crucial for ensuring images are displayed correctly on the exam papers without distortion.
def get_image_height(image_path, width):
with Image.open(image_path) as img:
aspect_ratio = img.width / img.height
return width / aspect_ratio
Finally, the space_left function is integral to managing page space and ensuring content doesn’t overflow onto the next page. By subtracting the current Y-coordinate (the point where the next content will be placed) from the total height of an A4 page (297mm in portarait mode), it computes the remaining vertical space on the current page. This function is particularly useful when deciding whether to insert an image or move to a new page to prevent content clipping or overlap.
def space_left(pdf):
return 297 - pdf.get_y()
Creating Exams and solutions files
The create_exam_and_solution function is the core of the script, it manage the creation of both exam papers and solutions based on the provided data. It takes in two dataframes (mcq_df and open_df), the number of exam copies (num_copies), and the counts of multiple-choice questions (mcq_count) and open questions (open_count) to be included in each exam.
def create_exam_and_solution(mcq_df, open_df, num_copies, mcq_count, open_count):
# .tex file generator
env = Environment(loader=FileSystemLoader('.'))
template = env.get_template('exam_template.tex')
for copy_num in range(1, num_copies + 1):
mcq_sample = mcq_df.sample(mcq_count).reset_index(drop=True)
open_sample = open_df.sample(open_count).reset_index(drop=True)
pdf_exam = PDF()
pdf_exam.add_page()
# Title
pdf_exam.set_font('Arial', 'B', 18)
pdf_exam.cell(200, 10, txt="xxxxxx Exam", ln=True, align='C')
# Subtitle
pdf_exam.set_font('Arial', 'B', 14)
pdf_exam.cell(200, 10, txt="Multiple Choice - 90' ", ln=True, align='C')
# Space for the student's details
pdf_exam.ln(10)
pdf_exam.cell(40, 10, txt="Name: ", border='B', ln=0)
pdf_exam.cell(60, 10, "", border='B', ln=True)
pdf_exam.cell(40, 10, txt="Surname: ", border='B', ln=0)
pdf_exam.cell(60, 10, "", border='B', ln=True)
pdf_exam.cell(40, 10, txt="ID: ", border='B', ln=0)
pdf_exam.cell(60, 10, "", border='B', ln=True)
pdf_exam.ln(10) # Add some space after the details section
# Questions start here
pdf_exam.set_font('Arial', size=12)
pdf_exam.cell(200, 10, txt="Exam {}".format(copy_num), ln=True, align='C')
pdf_solution = PDF()
pdf_solution.add_page()
pdf_solution.set_font('Arial', size=12)
pdf_solution.cell(200, 10, txt="Solution Copy {}".format(copy_num), ln=True, align='C')
for index, row in mcq_sample.iterrows():
shuffled_options, correct_position = shuffle_mcq_choices(row)
question_text = f"{index + 1}. {row['Question']}"
pdf_exam.multi_cell(0, 10, txt=question_text)
image_path = row.get('Image_Path', None)
if pd.notna(image_path):
if os.path.exists(image_path):
img_width = 90
img_height = get_image_height(image_path, img_width)
if space_left(pdf_exam) < img_height:
pdf_exam.add_page()
pdf_exam.image(image_path, x=10, y=pdf_exam.get_y(), w=img_width)
pdf_exam.ln(img_height + 5) # Added a 5mm padding after the image
else:
print(f"Image not found for path {image_path}")
for idx, opt in enumerate(shuffled_options):
choice_text = f" {chr(97 + idx)}. {opt}"
pdf_exam.multi_cell(0, 10, txt=choice_text)
solution_text = f"{index + 1}. Correct Answer: {chr(97 + correct_position)}"
pdf_solution.multi_cell(0, 10, txt=solution_text)
# .tex file creation
questions = []
for index, row in mcq_sample.iterrows():
shuffled_options, correct_position = shuffle_mcq_choices(row)
question_text = row['Question']
choices = [{'letter': chr(97 + idx), 'text': opt} for idx, opt in enumerate(shuffled_options)]
questions.append({
'type': 'mcq',
'text': question_text,
'choices': choices,
'solution': chr(97 + correct_position)
})
for index, row in open_sample.iterrows():
question_text = row['Questions']
questions.append({'type': 'open', 'text': question_text})
with open(f"Exam_Copy_{copy_num}.tex", 'w') as f:
f.write(template.render(questions=questions, copy_num=copy_num))
for index, row in open_sample.iterrows():
question_text = f"{index + 18}. {row['Questions']}"
pdf_exam.multi_cell(0, 10, txt=question_text)
# Check and insert image if present
image_path = row.get('Image_Path', None)
if pd.notna(image_path) and os.path.exists(image_path):
img_width = 90
img_height = get_image_height(image_path, img_width)
if space_left(pdf_exam) < img_height:
pdf_exam.add_page()
pdf_exam.image(image_path, x=10, y=pdf_exam.get_y(), w=img_width)
pdf_exam.ln(img_height + 5)
pdf_exam.output(f"Exam_Copy_{copy_num}.pdf")
pdf_solution.output(f"Solution_Copy_{copy_num}.pdf")
Initialization of LaTeX Template Engine:
The function begins by setting up the Jinja2 environment and loading a TeX template file named exam_template.tex. This will be used later for generating .tex files.
Exam and Solution Generation Loop:
A loop runs from 1 to num_copies + 1, representing the copy number of each exam defined by the user. For each copy:
- Random samples of MCQs and open questions are drawn from mcq_df and open_df respectively, according to mcq_count and open_count.
- Two PDF instances are created: pdf_exam for the exam paper, and pdf_solution for the solutions.
PDF Header and Student Details Section:
The exam paper’s header, including the title, subtitle, and student details section, is created using FPDF methods to set the font, add cells, and create new lines.
MCQ Section Construction:
The script iterates through the sampled MCQs. For each MCQ:
- It shuffles the answer choices using shuffle_mcq_choices.
- Writes the question text to pdf_exam.
- If an image path is provided and valid, it calculates the image’s dimensions, checks if there’s enough space on the current page, possibly adds a new page, and then inserts the image.
- Writes the shuffled answer choices to pdf_exam.
- Constructs a solution text and writes it to pdf_solution.
LaTeX File Construction for MCQs:
A list named questions is created to hold question data for the LaTeX file. It iterates through the MCQs again, shuffling the answer choices, and collects question data in a format suitable for rendering with the LaTeX template.
Open Questions Section Construction:
The script iterates through the sampled open questions:
- Collects question data for the LaTeX file similarly to the MCQs.
- Writes each open question to pdf_exam.
- If an image path is provided and valid for an open question, it handles image insertion in a manner similar to the MCQs.
TeX File Writing:
A new .tex file named Exam_Copy_copy_num.tex is created and written with the rendered LaTeX template using the collected question data.
PDF File Output:
Finally, the constructed pdf_exam and pdf_solution are saved to Exam_Copy_copy_num.pdf and Solution_Copy_copy_num.pdf files respectively.
Main Execution
The main function is where the script begins executing. Initially, it reads two Excel files containing data for multiple-choice and open-ended questions into Pandas DataFrames. It then asks the user to specify the number of exam copies to create, and the number of multiple-choice and open-ended questions to include in each exam through input prompts. These values are stored in variables num_copies, mcq_count, and open_count respectively.
def main():
mcq_df = pd.read_excel("mcq_input12.xlsx", engine='openpyxl')
open_df = pd.read_excel("open_input1.xlsx", engine='openpyxl')
num_copies = int(input("Enter the number of exam copies you want to create: "))
# Ask the user for the number of MCQs and open questions
mcq_count = int(input("Enter the number of multiple-choice questions you want in each exam: "))
open_count = int(input("Enter the number of open questions you want in each exam: "))
create_exam_and_solution(mcq_df, open_df, num_copies, mcq_count, open_count)
if __name__ == "__main__":
main()
Following this, the create_exam_and_solution function is called with the DataFrames and user-specified values as arguments, which triggers the process of creating the exam and solution PDFs. Lastly, the script’s entry point is defined to ensure main is called when the script is run directly, initiating the entire process.
Conclusion
This was merely an initial, raw attempt. Anyone who wishes to contribute to enhancing the project is welcome to do so via the GitHub repo.
Future goals include:
-
Math Formulas: Right now, the tool’s a bit clunky when it comes to adding math formulas. I want to make this smoother so that complex equations can be added easily.
-
Better LaTeX Design: I’ve noticed the exam class in LaTeX has some cool features I’m not using yet. I’m thinking of tweaking the .tex template to make the most out of what LaTeX has to offer.
-
Organized Questions: I’m planning to add an option where you can group questions into different sections.
-
Individual Exam Versions: I know some teachers might want every student to have a totally different exam. So, I’m looking into a feature that lets you create unique versions for each student.
-
Simpler Interface: Lastly, I’m hoping to build a better user interface. I want it to be easy for anyone to jump in and create an exam without getting messy in the technical stuff.
Alessio Garau
PhD student in economics
I’m a PhD student at Univeristy of Cagliari. My research interests include Labor Economics and Applied Microeconomics. Here you’ll find post about things i learn and some personal opinions.